SGlang
SGLang is a high-performance open source serving framework for large language models and multimodal models. It is designed to deliver low-latency and high-throughput inference across a wide range of setups, from a single GPU to large distributed clusters.
It is recommended by the engineering team of Apertus, and our Scratchpad repo has an example configuration. You can also find usage guidelines from Hugging Face.
Please visit the official website and documentation for further deployment instructions. For practical examples and tutorials, open the SGLang quickstart.
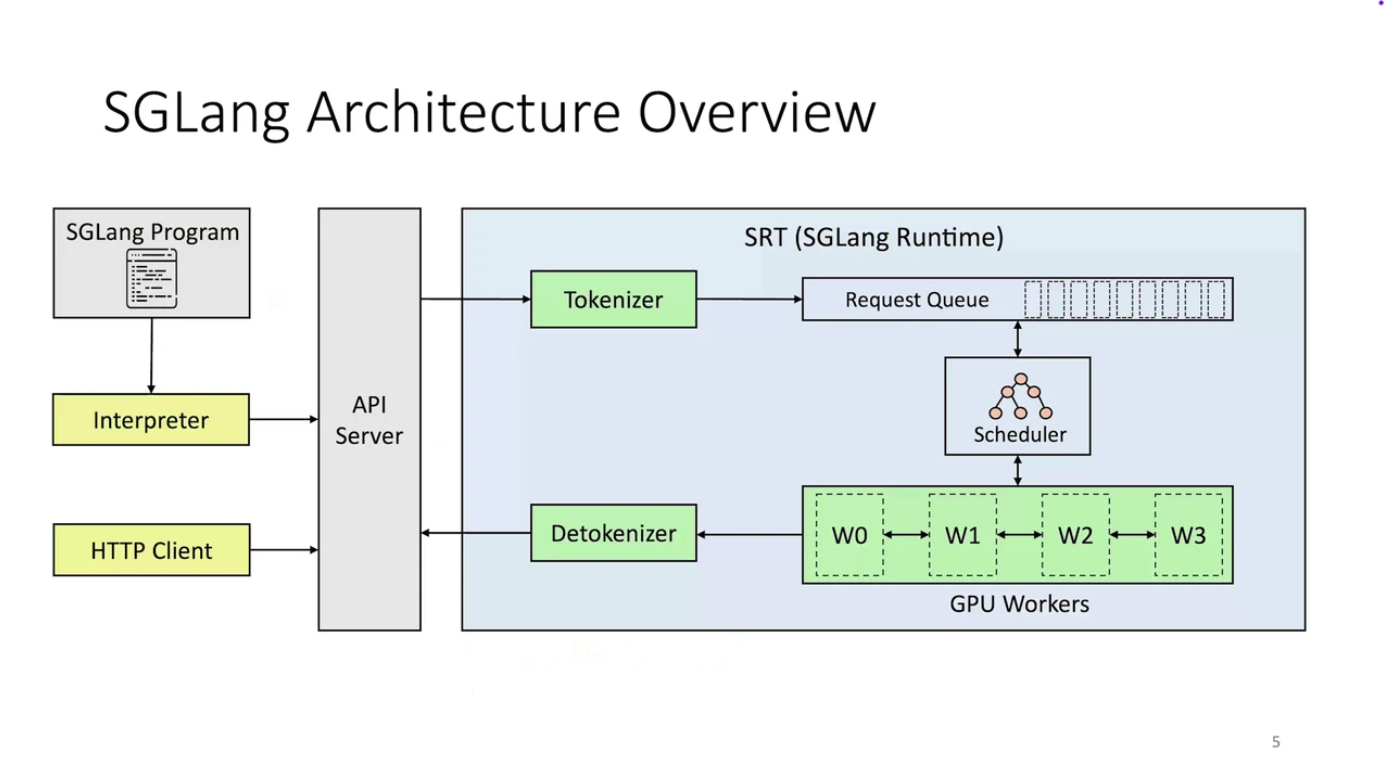 Diagram from Getting started with SGLang by Wilson Wu
Diagram from Getting started with SGLang by Wilson Wu
Overview
Key features of SGLang include:
- Efficient Backend Runtime: Uses RadixAttention, prefix caching, and other optimizations to speed up inference. This reduces latency and increases throughput, making it ideal for production environments.
- Flexible Frontend Language: Offers intuitive APIs for generating text, controlling model behavior, and managing complex prompts. This allows developers to craft detailed, context-dependent responses without diving into low-level details.
- Model Compatibility: Supports a wide range of models (e.g., Llama, Gemma, Qwen), making it easy to experiment with different set-ups.
- Open-Source and Community-Driven: Backed by a growing community, ensuring active development and support. This means frequent updates, new features, and access to community examples and troubleshooting resources.
For LLM developers, SGLang streamlines the deployment process with:
- Quick Deployment: With minimal configuration, you can set up a server to serve a model, leveraging your GPU resources efficiently.
- Customizable: Provides control over model parameters (e.g., max context length, temperature, batch size) to fine-tune performance and behavior.
- Streaming Support: Ideal for real-time applications like chatbots or live interactions, allowing continuous generation without blocking.
- Production-Ready: Supports scaling, concurrency, and integration with cloud platforms (e.g., via Kubernetes), making it suitable for large-scale use cases.
For production use, consider deploying SGLang with Kubernetes, e.g., using the OME operator or SkyPilot for cloud-scale setups.